
YLD discuss a practical use case for adopting Snowflake and its capabilities to accelerate the extraction of value from extensive data repositories.
Unlike digital platforms where viewer engagement and interaction can be easily tracked, the world of live TV broadcasts presents limited and ambiguous opportunities to capture detailed data on viewer preferences and behaviours.
Because of this, a YLD client made the executive decision to replace their legacy Business Intelligence APIs with a new approach based on Snowflake and configurable and dynamic insights. Through this approach, adopting Snowflake would provide the business with significantly more opportunities to generate more value from its vast amounts of data in a performant way.
This involves generating Snowflake queries and dynamic tables based on a configuration format with the data and parameters required for each visualisation, without compromising performance.
YLD used Terraform to create Snowflake infrastructure, including databases, schemas, roles, and users, adhering to best practices for infrastructure-as-code. The team leveraged Snowflake’s dynamic tables to easily create and update aggregation tables via configurations submitted to an API they built.
With everything in place, YLD created an engine capable of transforming these configurations into queries and dynamic tables. This approach harnesses the existing data and automatically prepares new datasets to serve the data requirements of dashboards being added or altered.
The diagram below portrays how YLD leveraged Snowflake source tables, facilitating the generation of pre-aggregated tables through the API. These tables are meticulously processed to meet specific requirements. Subsequently, the API dynamically generates SQL queries, transmitting them to Snowflake for execution. Snowflake processes these queries, yielding the desired output results.
The entire process integrates into the code deployment workflow which automates the creation and deletion of dynamic tables from a user interface. The process also represents an approach that enhances developer productivity by simplifying system interactions.
Additionally, the architecture supports real-time data ingestion, and Snowflake’s built-in connectors handle incoming data, eliminating the need for complex data management. This feature ensures a straightforward and efficient real-time data processing mechanism, contributing to the overall agility and responsiveness of the system.
Figure 1: YLD’s implementation and Snowflake workflow in an ongoing client project

Smooth data management with integrated dashboards
The client’s decision to transition all their source data to Snowflake prompted YLD to develop data tables on top of the source data, including dynamic tables queried through an API. Snowflake’s unique feature of dynamic tables simplifies the construction of data pipelines by enabling users to define transformations using SQL, with Snowflake ensuring the data is up-to-date.
Due to simplified data pipelines, users can seamlessly create a sequence of tables to perform various transformations, starting from pulling raw data to deriving actionable insights.
YLD’s proof-of-concept aims to significantly speed up dashboard loading times utilised by executives across both web and mobile app versions. These dashboards are designed for company-wide access, aimed at optimising backend computation in real-time to fulfil requests efficiently. Pre-aggregation tables and Snowflake results caching play pivotal roles in achieving this optimisation.
Choosing Snowflake for effective data management
Snowflake is a versatile analytics database often referred to as “Data Warehouse as a Service” (DWaaS), distinguished by its multi-cluster architecture. Its strength lies in efficiently managing diverse workloads, facilitated by its elastic performance engine.
This flexibility is emphasised by Snowflake’s integration with major cloud providers, enabling deployment on all major cloud platforms: Azure, AWS, and Google Cloud Platform (GCP). The platform excels at bringing together various data structures into one organised storage that guarantees secure handling and access.
Additionally, Snowflake improves operations by using the extensive scalability of cloud platforms to eliminate the need for tedious infrastructure management. It is easy to scale up or down quickly and efficiently by altering the server’s capacity in two ways:
- Vertically: changing the capacity of existing services.
- Horizontally: adding more servers to spread the workload.
The server capacity can be easily adjusted with a single SQL command that automates the process through scripts to create a Virtual Warehouse with a uniform and automated environment.
Data sharing is made simple with Snowflake because of its user-friendly “plug-and-play” approach that requires minimal maintenance efforts compared to other data cloud alternatives.
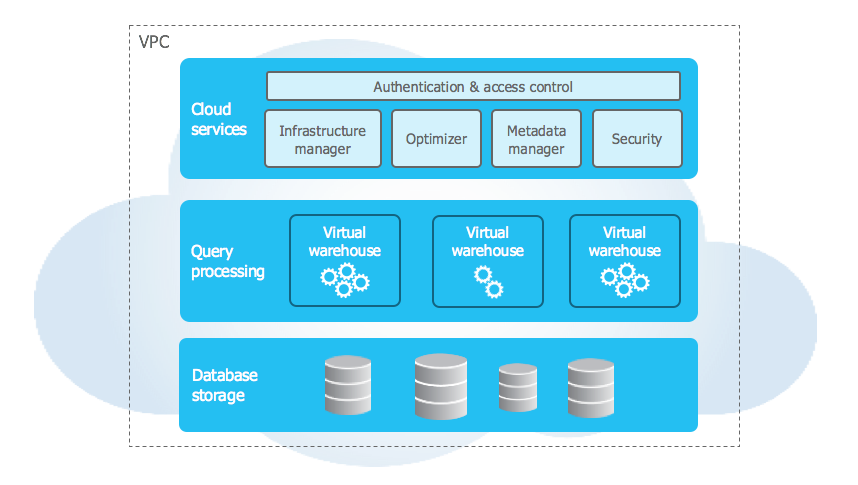
Here is a brief look at Snowflake’s architecture, highlighting its user-oriented design that simplifies scaling as needed:
- Database Storage: At the core of Snowflake, data is stored, accommodating structured and unstructured data types, including formats like Avro, Parquet, and JSON.
- Query/ Compute Processing Layer: Also known as “virtual warehouses”, this serves as the processing powerhouse. Virtual warehouses can also easily scale based on demand. All queries are executed in this layer, even though the data originates from the data storage. Other virtual warehouses fetch data from the central data store, serving as the true workers of Snowflake.
- Services: This is the entry point into the Snowflake architecture and handles all requests. It encompasses user authentication, management of virtual warehouses, and oversees the overall scalability and connectivity aspects of Snowflake.
Figure 2: Snowflake’s multi-cluster architecture
Choosing the right analytics database
The market is full of OLAP databases, so business decision-makers are on the lookout for the options that suit their use cases without limiting their options for the future. They need performance, features, and versatility. It’s in that sweet spot that Snowflake shines.
Snowflake’s database architecture has separate storage and compute layers, meaning the processing power can easily be moved to where the workload is needed most, resulting in a cost-efficient approach.
In comparison to Snowflake, Databricks has a similar structure with separate storage and compute layers. Notably, Databricks distinguishes itself by offering HASH integrations that enhance query aggregation speed, while Snowflake is recognised for its user-friendly “plug-and-play” approach that requires minimal maintenance.
Alternatively, Redshift AWS is a contender to Snowflake as it is a type of data warehouse that organises information in columns, meaning it can handle massive amounts of data, scaling up to petabytes. The benefit of using column-based storage is that it makes data compression and retrieval simpler. Additionally, it seamlessly works with BI tools, third-party data integration tools, and analytical tools. Ultimately, businesses may tend to switch to using Redshift AWS over Snowflake if their products are heavily AWS-focused, as it flawlessly fuses with the AWS ecosystem.
Having explored alternative data warehouse options, ultimately, Snowflake’s unique feature is its elastic performance engine.
There is a dedicated storage layer that allows flexible scaling of compute clusters based on specific requirements, so workloads can easily be scaled up or down, depending on the need. The virtual warehouses use a central data repository for stored data that is accessible from all computing nodes in the platform. This enables smooth, simultaneous background processing without concerns about performance issues.
Additionally, Snowflake has a few features that significantly support and manage demanding requirements:
- It is designed for efficient querying over large datasets.
- Its results caching feature helps speed up repeated queries even more.
- The results caching feature also handles cache invalidation, i.e. updating the cache as soon as the underlying data has changed, preventing stale data from being sent to the interface.
The creation of pre-aggregated datasets could also be easily managed using Snowflake’s dynamic tables feature. A simple SQL command can create these tables, and then Snowflake manages the process of keeping these tables up to date whenever the source tables receive more data. The lag at which the dynamic tables update can be configured to be as low as a minute, meaning they can also be used to create near real-time data pipelines as well.
Enhance your data practices
Data has been and continues to be crucial to modern businesses. It allows decision-makers to get insights that inform decisions, it helps product owners understand their product and adapt to usage signals, and with the emergence of GenAI, it allows companies to extract new values from it. Having strong data engineering practices and tools is crucial. Tools like Snowflake contribute to this, but YLD’s expertise in Data Engineering, MLOps, Data Science, Data Analysis, and Software Engineering can seamlessly integrate everything in a value-driven way.
Please contact YLD to discuss potential projects.
***

We’re excited to announce CTO Craft Con: London 2025, taking place this March!
Now in its fourth edition, this event brings cutting-edge content, top-tier speakers, and hands-on experiences designed to inspire, challenge, and empower you.
But this event isn’t about us—it’s about you. It’s about the practical insights you’ll take away and the genuine connections you’ll make with industry peers, all within a community that champions diversity and inclusivity.
Find out more here: https://conference.ctocraft.com/london-2025/
Join now to become a member of the free CTO Craft Community, where you’ll get exclusive access to Slack channels, conference insights and other valuable content. Subscribe to Tech Manager Weekly for a free weekly dose of tech culture, hiring, development, process and more.
